
Beginner’s Guide To Object Detection
Understand the pivotal computer vision task of object detection by seeing how one of the most popular models—YOLO— works.


What Is Object Detection?
Object detection is a computer vision task that aims to identify and locate objects within an image or video. Specifically, it draws bounding boxes around detected objects, enabling us to locate where the objects are and track how they move. It is often confused with image classification, so before we proceed, it's crucial that we clarify the distinctions between them.
Image classification merely assigns a class to an image. A picture of a single dog and a picture of two dogs are treated similarly by classification models and they both receive the label "dog". On the other hand, the object detection model draws a box around each dog and labels the box "dog". Here's an example of what this difference looks like in practice:

Image Classification vs Object DetectionGiven object detection's unique capability of locating and identifying objects, it can be applied in all kinds of tasks:
- Face detection
- Self-driving cars
- Video surveillance
- Text Extraction
- Pose estimation
This isn't an exhaustive list, it just introduces some of the primary ways in which object detection is helping shape the future of computer vision.
How Does Object Detection Work?
Now that we know a bit about what object detection is, and what it can be used for, let's understand how it actually works. In this section, we will take a look at the two broad paradigms of object detection models, and then explain the flow of the object detection process by elaborating on YOLO, a popular object detection model.
Two-Stage & Single-Stage Detectors
Two-stage models have two parts or networks, the initial stage consists of a region proposal model that extracts possible object regions from an image. A prime example of two-stage models is R-CNN that uses selective search to extract thousands of object regions for the second stage. The second stage model uses the local features of the object regions proposed by the initial stage to classify the object and to obtain a refined bounding box.
This separation of responsibility enables the second stage model to focus solely on learning the distribution of features for the object(s), making for a more accurate model overall. This added accuracy, however, comes at the cost of computational efficiency and thus two-stage detectors can't perform real-time detection on most systems.
Single-stage detectors, on the other hand, divide the input image into grid cells, and every single grid cell is associated with several bounding boxes. Each bounding box predicts an objectness probability(probability of the presence of an object), and a conditional class probability. Most grid-cells and bounding boxes see "background" or no-object regions and a few see the ground-truth object. This hampers the CNN's ability to learn the distribution of features for the objects leading to poor performance, especially for small objects. On the flip side, the model generalizes well to new domains.
YOLO - You Only Look Once
The YOLO - You Only Look Once - network uses features from the entire image to predict the bounding boxes, moreover, it predicts all bounding boxes across all classes for an image simultaneously. This means that YOLO reasons globally about the full image and all the objects in the image. The YOLO design enables end-to-end training and real-time speeds while maintaining high average precision.
 S x S grid
S x S grid
YOLO divides the input image into an S × S grid. If a grid cell contains the center of an object, it is responsible for detecting that object. Each grid cell predicts B bounding boxes and confidence scores associated with the boxes. The confidence scores indicate how confident the model is that the box contains an object, and additionally how accurate the box is. Formally, the confidence is defined as P(Objectness) x IOU_truthpred. Simply put, if no object exists in a cell, the confidence score becomes zero as P(Objectness) will be zero. Otherwise, the confidence score is equal to the intersection over union (IOU) between the predicted box and the ground truth.
 Bounding boxes and confidence scores
Bounding boxes and confidence scores
Each of these B bounding boxes consists of 5 predictions: x, y, w, h, and confidence. The (x, y) coordinates represent the center of the box relative to the bounds of the grid cell. The width(w) and height(h) are predicted relative to the whole image. The confidence prediction represents the IOU between the predicted box and any ground truth box.
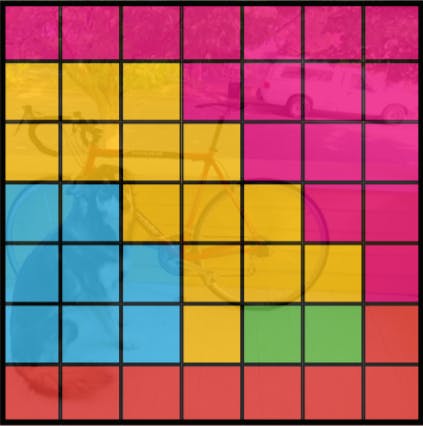 Class probability map
Class probability map
Each grid cell also predicts C conditional class probabilities, P(Class-i |Object). These probabilities are conditioned on the grid cell containing an object. Regardless of the number of associated bounding boxes, only one set of class probabilities per grid cell is predicted.
 Final detections
Final detections
Finally, the conditional class probabilities and the individual box confidence predictions are multiplied. This gives us the class-specific confidence scores for each box. These scores encode both the probability of that class appearing in the box and how well the predicted box fits the object.
YOLO performs classification and bounding box regression in one step, making it much faster than most CNN-based approaches. For instance, YOLO is more than 1000x faster than R-CNN and 100x faster than Fast R-CNN. Furthermore, its improved variants such as YOLOv3 achieved 57.9% mAP on the MS COCO dataset. This combination of speed and accuracy makes YOLO models ideal for complex object detection scenarios.

Do you want to solidify your knowledge of object detection and convert it into a marketable skill by making awesome computer vision applications like the one shown above? Enroll in AugmentedStartup's YOLOR course here today! It is a comprehensive course on YOLOR that covers not only the state-of-the-art YOLOR model and object detection fundamentals, but also the implementation of various use-cases and applications, as well as integrating models with a web UI for deploying your own YOLOR web apps.
This post is a part of my crossposts series which means I wrote this for someone else, the original article has been referred to in the canonical URL and you can read it here.