


With the advent of better and faster computer vision models, panoptic driving perception systems have become an essential part of autonomous driving. So much so that companies like Comma.ai are ditching additional sensors like Lidars and radars altogether. To help the driving system navigate the vehicle, the perception system needs to extract visual information from the surrounding information. Three of the primary requirements are:
- Detecting traffic objects
- Segmenting the drivable area
- Detecting lanes
There are numerous state-of-the-art algorithms that handle each of these tasks separately. Take for instance Mask R-CNN and YOLOR for object detection, or models like UNet and PSPNet for semantic segmentation. Despite their excellent individual performances, processing each of these tasks one by one takes a long time. In addition to that, the embedded devices these models are ultimately deployed have very limited computational resources, this makes the sequential approach even more impractical.

These traffic scene understanding tasks have a lot of related information, for example, the lanes often mark the boundary of the drivable area, and most traffic objects are generally located within the drivable area. YOLOP, You Only Look Once for Panoptic Driving Perception, takes a multi-task approach to these tasks and leverages the related information to build a faster, more accurate solution.
Architecture & Approach
YOLOP has one shared encoder and three decoder heads to solve specific tasks. There are no complex shared blocks between different decoders to keep the computation to a minimum and allow for easier end-to-end training.
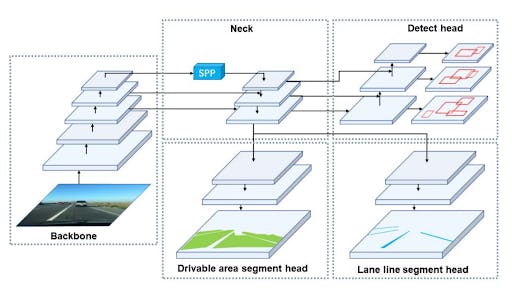
Encoder
The encoder consists of a backbone network and a neck network. YOLOP employs the lightweight CSPDarknet as the backbone, which is used to extract features from the input images. It supports feature propagation and reuse, which reduces the number of parameters and calculations. The neck network is responsible for feature engineering, it manipulates the extracted image features to get the most out of them. It consists of a Spatial Pyramid Pooling (SPP) module and a Feature Pyramid Network (FPN) module. The SPP model generates and fuses features of different scales, and the FPN module fuses features at different semantic levels. Thus, the neck network generates rich features containing multiple scales and multiple semantic level information. (Here, concatenation is used to fuse the features.)
Decoders
For the object detection task, YOLOP adopts an anchor-based multi-scale detection technique similar to that of YOLOv4. There are two reasons behind this choice, firstly the single-stage detection networks are faster than the two-stage detection networks. Secondly, the grid-based prediction mechanism is more relevant to the other two semantic segmentation tasks. The YOLOP detect head is composed of a Path Aggregation Network. The FPN in the neck network transfers semantic features top-down, and PAN transfers image features bottom-up. YOLOP combines them to obtain a better feature fusion effect, the multi-scale fusion feature map thus obtained is used for detection. If you want to learn more about how the grid-based detection mechanism works, check out this in-depth explanation.
The drivable area segmentation head and the lane line segmentation head use the same network structure. The features of size (W/8, H/8, 256) from the bottom layer of the FPN are fed to the segmentation branch. It applies three upsampling processes and restores the feature map to (W, H, 2), which represents the pixel-wise probability for the drivable area and lane line in the input image. Where other segmentation networks would have an SPP module, the YOLOP segmentation heads don’t need one because of the shared SPP module in the neck network.
Loss Functions & Training Methodology
YOLOP employs straightforward loss functions, it has three individual loss functions for the three decoder heads. The detection loss is the weighted sum of classification loss, object loss, and bounding box loss. Both loss functions of drivable area segmentation head and lane line segmentation head contain cross-entropy loss with logits. The lane line segmentation has an additional IoU loss for its effectiveness in predicting spare categories. The overall loss function of the model is a weighted sum of all three losses.

The creators of YOLOP experimented with different training methodologies. They tried training end to end, which is quite useful in cases where all tasks are related. Furthermore, they also examined some alternating optimization algorithms which train the model step by step. Where each step focuses on one or multiple related tasks. What they observed is that the alternating optimization algorithms offer negligible improvements in performance, if any.
Results
YOLOP was tested on the challenging BDD100K dataset against the state-of-the-art models for the three tasks. It beats Faster RCNN, MultiNet, and DLT-Net in terms of accuracy for the object detection task and can infer in real time. For the drivable area segmentation task, YOLOP outperforms models like MultiNet and DLT-Net by 19.9% and 20.2%, respectively. Moreover, it is 4 to 5 times faster than both of them. Similarly, for the lane detection task, it outperforms the existing state-of-the-art models by a factor of up to 2.
It is one of the first models— if not the first— model to perform these three tasks simultaneously in real-time on an embedded device like Jetson TX2 and achieve state-of-the-art performance.
How Well Does YOLOP Hold Up Against YOLOR & YOLOX?
The YOLO series has seen a lot of developments in 2021. In an earlier article, we compared YOLOR and YOLOX, two state-of-the-art object detection models, and concluded that YOLOR is better in terms of performance and general-purpose use whereas YOLOX is better suited for edge devices. With the introduction of YOLOP, a question now arises - “where does YOLOP fit in all this?” And the short answer is - it doesn’t really fit there at all.

You see, both YOLOX and YOLOR, regardless of their different approaches aim to solve the general-purpose object detection task. On the other hand, YOLOP was created solely for the purpose of traffic scene understanding, this is reflected in its design choices and its performance when it is trained to perform only object detection(as can be observed in the table above).

Do you want to learn one of the most pivotal computer vision tasks—object detection—and convert it into a marketable skill by making awesome computer vision applications like the one shown above? Enroll in AugmentedStartup's YOLOR course HERE today! It is a comprehensive course on YOLOR that covers not only the state-of-the-art YOLOR model and object detection fundamentals, but also the implementation of various use-cases and applications, as well as integrating models with a web UI for deploying your own YOLOR web apps.
This post is a part of my crossposts series which means I wrote this for someone else, the original article has been referred to in the canonical URL and you can read it here.